Hola compañeros y gente que regularmente visita mi blog, esta entrada corresponde a la tarea 5 de la materia de Redes de Telecomunicaciones. La entrada consiste en la realización de experimentos de congestión, desde la creación de una topología, generación de tráfico y realización de esquemas de control de congestión.
Bien, una de las cosas teóricas que recuerdo de la clase de transmisión de datos es el tema de windowing que consiste en evitar la pérdida de paquetes debido a al desborde del buffer del dispositivo receptor, de manera que cuando el buffer está lleno, el emisor deja de enviar paquetes, luego continua cuando se aligere la carga del mismo. Esto además de evitar la pérdida de paquetes también podría intervenir positivamente para evitar la congestión de la red, porque se deja de enviar tráfico que no serviría de nada porque se tiraría al llegar al buffer desbordado. Lo que yo realizé fue una especie de este feature en el ns2. Leo el número de bytes recibidos, luego con una simple comparación (simulación de buffer) de cuando el buffer está lleno, reseteo la transmisión. El código tcl es el siguiente:
Las trazas obtenidas para las 2 instancias de tráfico son las siguientes:
Laboratorio 9 - Energy - Efficient Antenna Sharing and Relaying for Wireless Networks
Hola compañeros y gente que regularmente visita mi blog, esta entrada corresponde a la actividad número 9 del laboratorio de Redes de Telecomunicaciones. Consiste en elaborar un resumen y dar mi punto de vista de un tema que trata deldesarrollo de protocolos de transmisión en las redes wireless que hacen un eficiente uso de la energía.
El documento investigado está titulado con el nombre de Energy-Efficient Antenna Sharing and Relaying for Wireless Networks, los autores son J. Nicholas Laneman and Gregory W. Wornell.
La transmisión de informacióna través devariosenlaces de comunicaciónpunto apuntoes uncomponente básico delas redes de comunicación. Esta transmisiónse utiliza enredes cableadase inalámbricaspara lograr una mayorconectividad de la red(la coberturamás amplia), la utilización eficiente de recursoscomo la energíay ancho de banda, mejores economíasde escala enel costode las transmisionesde larga distancia(a través dela agregación detráfico), la interoperabilidadentre las redesymás fácilmentemanejables.
En las redes inalámbricas,la transmisión directaentre radiosampliamenteseparadospuedeser muy costosa entérminos depotencia transmitidarequeridapara una comunicación fiable.Las transmisionesde alta potenciadescargan la bateríamás rápido (menorvida de la red).Como alternativas ala transmisión directa,hay dosejemplos básicosyempleados con frecuenciaen la transmisiónpararedes inalámbricas.En los entornoscelulares,por ejemplo, las redesproporcionan conectividadentre móvilesde baja potencia, proporcionando conexioneslocalesaestaciones basede alta potenciaque se transmitena través de unaestación basede redalámbrica.Enlas redes de sensoresy redes de comunicaciónde campo de batallamilitar engeneral, el usode la infraestructura delínea fijaes a menudoexcluidaylosradiospueden ser depotencialimitada;para estas redespeer-to-peerad-hocotransmisionesse pueden transmitirsin cables.
Las transmisiones end-to-end potencialmente incurren en mayor retraso (delay) pero debido a que las transmisiones individuales son en distancias más cortas (en el caso inalámbrico), o através de un cableado de alta calidad (en el caso de la telefonía fija) los requisitos de energía para una comunicación fiable pueden ser mucho menores.
En este trabajo, desarrollamosprotocolos detransmisión deenergía eficiente que crean yexplotanla diversidadespacialpara combatir el desfase debido a lapropagación por trayectos múltiples, una forma particularmenteseverade la interferencia,experimentadaen las redes inalámbricas.
Para ilustrarlos principalesconceptos, se considera la red inalámbricasencillaque se muestra en la siguiente imagen.
Nos centramosespecíficamente enlas transmisiones deradio 1, llamamos a lafuente, a la radio3, llamado eldestino,conla posibilidad de utilizarla radio2 comoun relé.En la capa física, eldestino recibeseñalespotencialmenteútiles a partir detodos los transmisoresque están activos, y se puedecombinar múltiplestransmisionesde la misma señalpara reducir las variacionesen el rendimientocausadas por el desfase de la señal, una técnica a que se refiereen términos generales comola combinación dediversidad espacial. Nos referimos aesta forma dediversidad espacialcomo el reparto dela antena, en contraste conlasformasconvencionalesen la actualidad másdela diversidadespacial, debido a que losradiosesencialmentecompartensusantenasy otros recursospara crearuna"matrizvirtual"a través dela transmisióndistribuiday procesamiento de señales.
Modelo del sistema
Ennuestro modelopara la red inalámbrica radio-tres representadoen imagen anterior, las transmisionesde banda estrechasufrenlos efectos de lapérdida de trayectoria. Nuestroanálisis se centra enel caso dedesfase lentopara aislarlosbeneficios de la diversidadespacialsola, sin embargo, hacemos hincapiéenel principiode quenuestrosresultadosse extiendennaturalmente alostipos deescenariosaltamentemóvilesen el queseencontróel desfasemás rápido. Nuestro modelode banda de base-equivalente de canal de tiempo discreto mostrado en la imagen anterior, consiste endossubcanalesortogonales. Esta descomposiciónes necesaria debido a que las limitaciones prácticasen la implementaciónde radioimpiden la retransmisión de recepciones y transmisiones simultaneas en el mismo canal.
Protocolos de transmisión
En el marcode capa físicaexaminamosvariosprotocolosque soportanla transmisión entre elorigen y el destino. Cadaprotocolo consiste enun formato demodulación de la fuente, unprocesamiento/modulación deretransmisión,y una estructura dereceptor dedestino.
Parasimplificar la exposición, tratamos transmisiones binariascon módulos constantes, de modo quela señal de origen transmitidax1[n] es blanca ytoma valoresx0yx1con igual probabilidad. Para habilitar la deteccióncoherente, los receptores de transmisióny de destino debenprimeroobtener, a través de secuencias de entrenamientoenlascabeceras de protocolo, las estimaciones precisas deloscoeficientes deenlacede desfase, en varios escenarios, el destino también utilizauna estimación deγ1,2. Suponemosque estas estimaciones son perfectasen nuestro análisispreliminar.
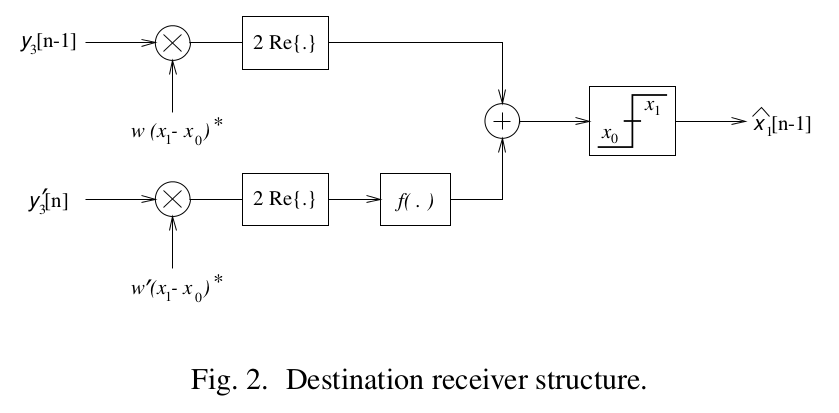
Todas nuestrasestructurasreceptorasde destinopuede ser implementadascomo se muestraen la siguiente imagen.
Este"combinador" puede ser visto comounfiltro adaptado, o de radio-máximo, modificado adecuadamentepara encajarel protocolo.
Transmisión singlehop
La transmisión singlehop, denominada a menudo enrutamiento singlehop por la comunidad de redes ad-hoc, consiste en la transmisión directa entre la fuente y los radios de destino (por eso singlehop, solo se realiza un solo "salto").
Transmisión multihop
La transmisiónmulti-hop ennuestro sistemapuede ser vista comola transmisiónsinglehopen cascadaentre la fuentey el transmisor, hasta el destino.
Simulaciones de rendimiento
Paracomparar el rendimientodelos protocolos de transmisión, examinamosuna redconcoordenadasnormalizadas porla distancia d1, 3entrela fuenteylas radiosde destino. Enestas coordenadas, la fuentepuede estar situada en(0, 0), yel destinopuede ser localizadoen(1, 0), sin pérdida de generalidad.
Crítica
La mayoría de las empresas que implementan varios enlaces de comunicación punto a punto no se preocupan por la eficiencia de la energía ya que su principal prioridad es la disponibilidad de la conexión, incluso en algunos enlaces redundantes el backup siempre está trabajando (aunque no se le necesite, es decir, siempre está activo). La eficiencia de la energía es, entre otros, features que agregan las compañías fabricantes para proveer un mejor servicio a los clientes, pero siempre resultan muy costosos estos equipos Energy-Efficient Antenna Sharing and Relaying for Wireless Networks: J. Nicholas Laneman and Gregory W. Wornell.
Research Laboratory of Electronics Massachusetts Institute of Technology Cambridge, MA 02139 USA
Laboratorio 8 - Predictive Congestion Control Protocol for Wireless Sensor Networks
Hola, esta entrada corresponde a la actividad de laboratorio número 8 y consiste en realizar un resumen y punto de vista sobre algún protocolo para evitar la congestión de red.
Autores: Maciej Zawodniok and Sarangapani Jagannathan
La congestión en la red, que es muy común en redes inalámbricas, ocurre cuando la carga excede la capacidad disponible. La congestión de la red hace que la calidad del canal se degrade y se elevan las tasas de pérdida. Esto nos lleva al dropeo de paquetes en los buffers , aumentan los retrasos, se desperdicia energía, se requieren retransmisiones. Por otra parte, el flujo de tráfico será injusto para los nodos cuyos datos tienen que atravesar un números significativo de saltos (saltos se refiere a la cantidad de nodos por los que tiene que pasar). Todo esto reduce considerablemente el funcionamiento y el tiempo de vida de la red. Un mecanismo de control de congestión se necesita con el fin de equilibrar la carga, para evitar la pérdida de paquetes y para evitar el estancamiento de la red.
Metodología propuesta.
La congestión de red de la siguiente imagen se produce ya sea cuando el tráfico entrante (recibido y generado) excede la capacidad del enlace de salida o el enlace de ancho cae debido a un desfase de canal causado por la pérdida de trayectoria.
Descripción general del sistema propuesto.
La siguiente imagen representa un Deep Packet Capture (DPC) con una adaptación de velocidad.
La imagen puede ser resumida en los siguientes pasos:
1) El inicio de la congestión se detecta a partir de las ocupaciones del buffer en los nodos a lo largo de la potencia del transmisor predicho. El algoritmo de selección de la velocidad se ejecuta a continuación, en el receptor para determinar la tasa apropiada (o ancho de banda disponible) para el canal de estado predicho.
2) El ancho de banda disponible o tasa se asigna a los flujos de acuerdo a los pesos de flujo para asegurar la equidad ponderada. Los pesos pueden ser seleccionados inicialmente, luego se van actualizando con el tiempo. 3) La información DPC(Deep Packet Capture) y la tasa se comunica entre los nodos en cada enlace.
4)En el nodotransmisor,un intervalode interrupciónse selecciona utilizandoel esquema propuestobasado en la tasa de salida asignada. 5)Elesquema de adaptación depeso dinámicose puede utilizar paramejorar aún más elrendimiento a la vezasegurar la equidad. Los paquetesen cada nodo pueden ser programados mediante la programación adaptativa y distribuida (ADFS), a travésde flujo depesos asignadosque se actualizancon base en elestado de la redpara asegurarel manejojusto delos paquetes. Medidas de rendimiento.
Los paquetes perdidos en los nodos intermedios debido a la congestión causarán bajo rendimiento de la red y disminuirá la eficiencia de energía debido a retransmisiones. En consecuencia, el número total de paquetes perdidos en los nodos intermedios será considerado como una métrica para el protocolo diseñado. La eficiencia energética medida como el número de bits transmitidos por joule, será utilizado como la segunda métrica. La eficiencia de la red medida como el rendimiento total en la estación base se toma como una métrica adicional. La equidad ponderada se utiliza como un indicador, ya que la congestión producida puede causar un manejo injusto en los flujos. Control de congestión adaptativo.
El esquema de selección de frecuencia adaptativa cuando es implementada en cada nodo , actúa como una señal de presión de retorno para reducir al mínimo el efecto de la congestión sobre una base hop-by-hop mediante la estimación del flujo de tráfico de salida. Por consecuencia, la congestión es "coregida" por a) el diseño adecuado de vuelta fuera de intervalos para cada nodo basado en el estado del canal y el tráfico actual, y b) mediante el control de las velocidades de flujo de todos los nodos, incluyendo los nodos de origen para evitar un desbordamiento de buffer. Selección de la tasa de velocidad basada en ocupación de buffer. El esquema de selección de la velocidad tiene en cuenta la ocupación de memoria intermedia y una tasa de salida de destino. La tasa objetivo en el siguiente salto de nodo, indica cuál es la tasa de entrada que debe ser.
(Selección de la tasa entrante)
Resultados de simulaciones Los resultados de las topologías realizadas se obtuvieron por medio del simulador ns-2. Las simulaciones fueron configuradas para utilizar un canal de 2 Mbps con pérdida de trayectoria, sombra y desvanecimiento de Rayleigh con enrutamiento AODV. La siguiente imagen muestra la utilización de cola y la estimación del flujo de salida.
La siguiente imagen muestra el desempeño para la topología desbalanceada.
La imagen siguiente muestra el error de la utilización de colas y la estimación de error del tráfico de salida.
Por último, en la siguiente tabla se muestran las medidas de delay, throughput y eficiencia de la energía para los distintos protocolos.
Conclusiones Es claro que el sistema propuesto no resuelve a la perfección la congestión generada en las redes, pero como los autores mencionan, este sistema solamente ayuda a mitigar la congestión. Las condiciones de red mediante las cuales se trabaja y se realizaron las simulaciones incluyen el tráfico a través de una región determinada y el estado del canal, con respecto al tráfico, es una variable con un cambio muy difícil de predecir, y prácticamente imposible hacerlo a la perfección. Como consecuencia se obtienen sistemas que solamente mitigan la congestión, no en su totalidad, pero lo suficiente para aligerar el tráfico de las redes actuales. Predictive Congestion Control Protocol for Wireless Sensor Networks IEEE TRANSACTIONS ON WIRELESS COMMUNICATIONS, VOL. 6, NO. 11, NOVEMBER 2007 Autores: Maciej Zawodniok and Sarangapani Jagannathan
Hola, en esta ocasión vamos a monitorear las medidas de desempeño de la distintas transmisiones de datos en el simulador ns-2.
Las medidas que voy a evaluar es el throughput que es la cantidad de bits que se transmiten exitosamente por segundo, además de la latenciaque es la velocidad de propagación de la señal, que esta depende del medio por el que viaja la señal.
Transmisión simple de paquetes UDP sobre un protocolo de ruteo tipo DV
Bien, el primer caso que tenemos es el de una topología con 2 nodos corriendo un protocolo de ruteo tipo DV, la transmisión de paquetes es tipo UDP (esto es similar a la topología del laboratorio anterior). Mediremos el desempeño mediante el throughput y la latencia, como ya lo mencioné antes.
El código para obtener la topología mencionada es el siguiente:
Y la simulación en nam es esta.
Seguido de esto echamos un vistazo a nuestro archivo generado de trazas, este contiene el tiempo de llegada de paquetes y el tamaño de los paquetes transportados (por el agente), que son los que nos interesa para obtener la latencia y el throughput. Las siguiente son unas cuantas de las líneas que contiene el archivo de trazas "tr"
Graficaremos estos datos con la ayuda de gnuplot, pero para eso primero vamos a aplicar un filtrado con awk sobre los datos obtenidos, porque se puede notar que contiene caracteres que no le gustan a gnuplot. Tenemos un archivo awk para el filtrado de datos de la latencia y otro para el filtrado de datos del throughput.
Totalmente digeribles para gnuplot. Ahora solo generamos nuestro plot. Mi plot para la latencia es el siguiente, el eje x representa el tiempo transcurrido, mientras que el y representa el tamaño de los paquetes.
Plot para throughput
Realicé lo mismo pero ahora la transmisión de datos simula comunicación en Voz IP, igualmente por medio del protocolo de transporte UDP.
El código es el siguiente:
Y esta es la simulación en nam
Filtramos las trazas obtenidas con awk nuevamente y obtenemos los siguientes archivos para plotearlos con gnuplot.
Hola, esta entrada corresponde a la actividad 6 del laboratorio de redes de telecomunicaciones y trata sobre ruteo o enrutamiento, sobre topologías de red y protocolos de ruteo.
El ruteo es una parte escencial en el mundo de las redes, su propósito es encaminarnos desde nuestro orígen hacía el destino solicitado, determina mediante protocolos de ruteo el camino que tomarán los paquetes de información, y dependiendo del protocolo usado se establece la mejor ruta para enviar el paquete.
El dispositivo de red que cumple con está función se llama router, y está claro no elige la mejor ruta por arte de magia, a este dispositivo debemos configurarlo para que cumpla con las funciones requeridas. Existen 2 maneras para realizar la configuración, usando protocolos de ruteo dinámicos ó ruteo estático (hablaremos de esto más adelante).
En el ambiente académico no se suele estudiar o implementar a fondo las distintas topologías que puede tener una red de telecomunicaciones.
La topología de red se define como una familia de telecomunicación usada por las computadoras que conforman una red para intercambiar datos. [Definición formal, wikipedia]
Existen diversas topologías que podemos usar para implementar nuestra red, esto dependerá de la funcionalidad que tendrá nuestra red y de las características que queremos que tenga. La imagen de arriba muestra algunos ejemplos de topologías y a la vez demuestra la afirmación que acabo de hacer sobre la aplicación de ciertas topologías para ciertos propósitos; por ejemplo, si lo que queremos es tener una buena disponibilidad de red, es decir, no queremos pérdida de conexión debemos evitar topologías como la estrella, debido a que en este tipo de topologías, todos los nodos están conectados a un único nodo central, de manera que todo el tráfico realizado tiene que pasar por ese nodo central. Podemos concluir que si se cae ese nodo, toda la red quedaría sin comunicación. Este tipo de topología suele ser usada en redes locales, en hogares, en donde la disponibilidad de la conexión no es prioridad como en negocios que por caída de comunicación pierden mucho dinero.
A continuación describo algunas de las topologías que he implementado en casa y negocios (aunque sea en simulador :D).
Topología en estrella
Una red en estrella es una red
en la cual las estaciones están conectadas directamente a un punto
central y todas las comunicaciones se han de hacer necesariamente a
través de este. Los dispositivos no están directamente conectados entre
sí, además de que no se permite tanto tráfico de información. Dada su
transmisión, una red en estrella activa tiene un nodo central activo que normalmente tiene los medios para prevenir problemas relacionados con el eco.
Se utiliza sobre todo para redes locales. La mayoría de las redes de área local que tienen un enrutador (router), un conmutador (switch) o un concentrador
(hub) siguen esta topología. El nodo central en estas sería el
enrutador, el conmutador o el concentrador, por el que pasan todos los
paquetes de usuarios. [Más información]
Topología de anillo
Una red en anillo es una topología de red en la que cada estación tiene una única conexión de entrada y otra de salida. Cada estación tiene un receptor y un transmisor que hace la función de traductor, pasando la señal a la siguiente estación.
En este tipo de red la comunicación se da por el paso de un token o testigo, que se puede conceptualizar como un cartero que pasa recogiendo y entregando paquetes de información, de esta manera se evitan eventuales pérdidas de información debidas a colisiones. [Más información]
Topología anillo doble
En un anillo doble (Token Ring), dos anillos permiten que los datos se
envíen en ambas direcciones (Token passing). Esta configuración crea
redundancia (tolerancia a fallos). Evita las colisiones.
Este tipo de topologías la usan en los "core" o sistemas centrales de las empresas, aquí es donde corre el mayor flujo de datos que proveen de conectividad a toda la red, es por eso que se crea una redundancia (si una interfaz de un dispositivo falla, entra otra). En este tipo de topologías las configuraciones de ruteo y switcheo se realizan con protocolos de rápida convergencia,y que sean óptimos en los tiempos. Lo que se evita es que haya demasiado tráfico innecesario en esta topología. También se usan equipos de red muy sofisticados.
Como había comentado anteriormente, para configurar los ruteadores tenemos dos opciones: usar protocolos dinámicos o mediante rutas estáticas.
En experiencias que tuvimos en clases de transmisión de datos recordamos que la configuración de equipos por medio de rutas estáticas es muy pesado, en especial en topologías que cuentan con muchos ruteadores, porque hay que ir configurando en cada uno de ellos todas las segmentos de red que existen en la topología.
Todo lo contrario a a las rutas estáticas son los protocolos dinámicos, que los configuramos en cada uno de los equipos que queremos routear y luego ellos se encargan de ir llenando su tabla de enrutamiento con los mejores caminos que ellos determinan (el mejor camino depende de el protocolo que uses). Dentro de los protocolos de ruteo dinámico se encuentran: RIP, RIPv2, EIGRP, OSPF (usados en clase de transmisión de datos).
Link State
Estado de enlace se basa en que un router o encaminador comunica a los restantes nodos de la red, identifica cuáles son sus vecinos y a qué distancia está de ellos. Con la información que un nodo de la red recibe de todos los demás, puede construir un "mapa" de la red y sobre él calcular los caminos óptimos. El encaminamiento por estado de enlace nace en 1979 cuando en ARPANET sustituyó al método de vector de distancias. [Más información]
Distance Vector
El Vector de distancias es un método de enrutamiento. Se trata de uno de los más importantes junto con el de estado de enlace. Utiliza el algoritmo de Bellman-Ford para calcular las rutas. Fue el algoritmo original de ARPANET. Se usó en DECNET, IPX y Appletalk. Lo usa el protocolo RIP (Routing Information Protocol), que hasta 1988 era el único utilizado en Internet. También se utiliza en los protocolos propietarios ampliamente extendidos IGRP y EIGRP de Cisco. [Más información]
Para esta actividad hicimos uso del método de enrutamiento distance vector, método usado por los protocolos de ruteo dinámico RIP y EIGRP.
El siguiente es el código tcl realizado para 10 nodos, después de realizar la simulación abrí nam en el mismo código para que se ejecutara el modo gráfico:
El resultado obtenido es el siguiente:
Cualquier duda o aclaración pueden dejarla en comentarios.